ptcg
1. 关于data/ptcg下各文件的用途和关系
1.1 agent-workflow-memory(不是这个项目的?)
AWM(代理工作流) 是一种预先定义或者存储的agent的“工作蓝图”,其可以看成是agent的“记忆”,用于指导LLM完成各种复杂的任务。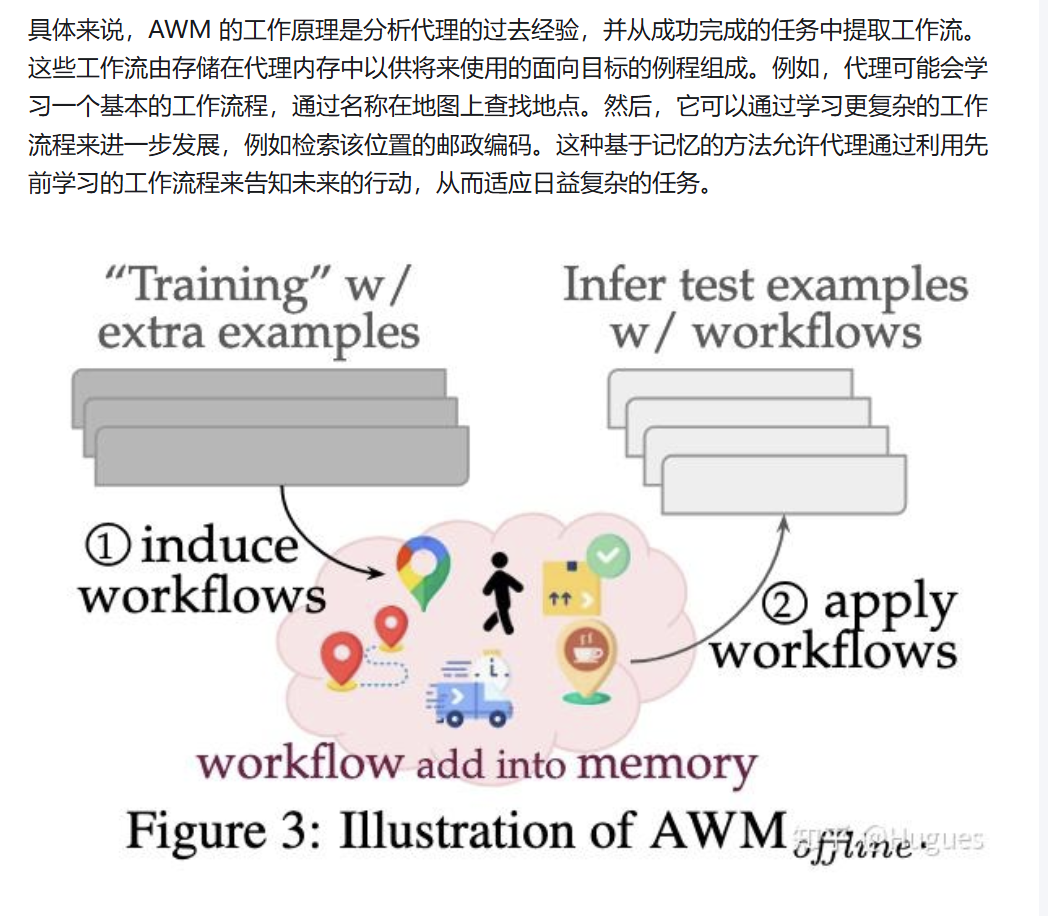 该父文件夹下的 mind2web以及webarena应该都是附带的基准测试文件
该父文件夹下的 mind2web以及webarena应该都是附带的基准测试文件
1.2 ClaudePlaysPokemonStarter
这是一个用于将Claude AI用于play pokemon的红方的智能体系统
1.3 open spiel
“OpenSpiel 是 DeepMind 开发的一个专注于游戏强化学习研究的开源框架。它提供了一个丰富的游戏环境集合和算法实现,支持多种类型的游戏和研究场景。” 可以理解为是游戏强化学习的一个平台
1.4 open-ptcg
应该是主要的工程文件,里面除了包含了之前的整个ptcg的信息之外,还有一些额外的强化学习相关的内容。其中: #### 1.4.1 eval文件夹 eval文件夹中导入了对于训练好的模型进行评估的手段,其中各个文件的作用分别为: ##### (1) eval_sb3_ppo.py 这个文件是用来在训练的过程中定性观察训练出的agent在过程中采取的策略的文件,其对于单个环境进行可视化的演示,方便逐步调试以及观察游戏进程 ##### (2) eval_sb3.py 这个文件用于加载已经训练好的模型,并且评估模型在指定数量的episode中的表现,并且输出得到的奖励结果 ##### (3) eval_all.py 这是一个全方位的评估文件,可以用于多种智能体之间的对比和对战,其可以: 同时,创建出一个N*N的不同agent的对战胜利矩阵,以及跑完之后完整的wandb的实验记录和结果分析 ##### (4) evaluate.py 这个文件实现了一个交互式的游戏演示系统,其可以让你实现与AI对战或者实时观察两个智能体之间的战斗过程,是一个与前端相结合的交互式系统
同时,创建出一个N*N的不同agent的对战胜利矩阵,以及跑完之后完整的wandb的实验记录和结果分析 ##### (4) evaluate.py 这个文件实现了一个交互式的游戏演示系统,其可以让你实现与AI对战或者实时观察两个智能体之间的战斗过程,是一个与前端相结合的交互式系统
1.4.2 logs&models 文件夹
这两个文件夹应该是记录之前(以及之后)训练结果以及对战的各条log和记录
1.4.3 关于核心的代码架构
(1)关于action space的定义
在目录open-ptcg/ptcg/core下有一个spaces.py文件,里面对于action space有如下的定义: 1
2
3
4
5
6def _action_space() -> spaces.MultiDiscrete:
# 0 ~ 14: one-hot encoding for action type [0-1]
# 15: source card id [0-32]
# 16: target card id [0-32]
nvec = [2] * 15 + [33] * 2 + [2] * 20
return spaces.MultiDiscrete(nvec)1
2
3action = np.zeros(17, dtype=np.int8)
action[0] = self.playerId.value - 1 对于每一种动作,对应关系是这样的:
对于每一种动作,对应关系是这样的: 1
2elif isinstance(self, UseStadiumAction):
action[4] = 1
以上为action定义的第一部分编码部分
接下来的第二部分to_nl展示了如何把这些动作部分转化为易于直接阅读的log,与核心rl关系不大;后续的也多为基础架构的信息 简而言之,这个部分告诉了我们,玩家的每一回合做出的每一张卡牌的可能的动作都可以被转化为一个37维度的“向量”,方便后续的操作
(2) 关于不同state的定义
在目录open-ptcg/ptcg/core下有一个state.py文件,里面对于state的实现有如下定义: (0)首先是一段命名逻辑的转换: 1
2
3
4def _c2s(name):
s1 = re.sub("(.)([A-Z][a-z]+)", r"\1_\2", name)
s2 = re.sub("([a-z0-9])([A-Z])", r"\1_\2", s1)
return s2.lower() 会返回一个cardlist类型的对象,包含这个区域所有卡牌的信息 (3)def_todict方法:这个部分的作用是把玩家和当前场上的信息转化为一个序列化的字典结构(类似于json的结构),转化为类似如下的格式(同时,借助于上面的c2s实现标准化的文本转化):
会返回一个cardlist类型的对象,包含这个区域所有卡牌的信息 (3)def_todict方法:这个部分的作用是把玩家和当前场上的信息转化为一个序列化的字典结构(类似于json的结构),转化为类似如下的格式(同时,借助于上面的c2s实现标准化的文本转化): 这个的目的应该是方便给前端传递json文件(? (4)get_encoded_obs函数:这应该是与强化学习有关的比较核心的一个部分,用于将游戏状态编码成可以输入给强化学习环境的编码值,具体的实现分为以下的几个部分: 1. encode_pokemon(card):这个部分输入一张宝可梦卡牌,接着将其编码为一个长度为15的数组,当输入的卡牌信息的确为宝可梦卡牌时,会在不同的地方存储相应的信息,15个格子分别代表宝可梦的血量(除以10)、是否有攻击、攻击的伤害、宝可梦需要的能量种类和所需要的点数(不同的格子代表不同属性的能量,格子存储的值代表这种属性能量需要的点数)。在这个部分的后面,会接上一个代表这张卡牌编号的one-hot编码;也就是说,最后的宝可梦卡牌由两个部分组成,前一半是宝可梦的属性信息,后一半是宝可梦的编号信息 2. encode_card(card):对于其他的非宝可梦卡牌,直接使用one-hot编码表示。
这个的目的应该是方便给前端传递json文件(? (4)get_encoded_obs函数:这应该是与强化学习有关的比较核心的一个部分,用于将游戏状态编码成可以输入给强化学习环境的编码值,具体的实现分为以下的几个部分: 1. encode_pokemon(card):这个部分输入一张宝可梦卡牌,接着将其编码为一个长度为15的数组,当输入的卡牌信息的确为宝可梦卡牌时,会在不同的地方存储相应的信息,15个格子分别代表宝可梦的血量(除以10)、是否有攻击、攻击的伤害、宝可梦需要的能量种类和所需要的点数(不同的格子代表不同属性的能量,格子存储的值代表这种属性能量需要的点数)。在这个部分的后面,会接上一个代表这张卡牌编号的one-hot编码;也就是说,最后的宝可梦卡牌由两个部分组成,前一半是宝可梦的属性信息,后一半是宝可梦的编号信息 2. encode_card(card):对于其他的非宝可梦卡牌,直接使用one-hot编码表示。
以上的两个函数都在父函数encode_player(player)下面,这个函数下面还有以下的一些组成: 1.meta_info 编码:里面存储了一系列表示场上卡牌信息的内容,包括了当前是哪个玩家的回合、各个区域的卡牌数量以及各个玩家各个区域的卡牌数量等信息(纯记录数量的信息) 2.encode_card_list 和 encode_pokemon_list:用于对一个卡组进行编码,定义一个max_size,遍历card_list的所有卡片,对其中的每一张卡调用上面的方法生成编码;若卡牌数量小于max_size,那么空的地方用empty_card填充。(代码中定义了方法,即生成全为0的编码)
因此,这个state.py最终返回的信息是对于两个玩家,分别返回对应的字典,其中包含了meta_info以及一系列的编码后的卡牌向量信息。
总结一下,前两个部分分别展现了在ptcg卡牌的强化学习任务中的动作和状态是如何通过将其编码进行描述的,简单来说就是进行多采用one-hot的编码进行规范化的传递
(3)关于reward的定义
关于reward的定义在目录open-ptcg/ptcg/core下的reward.py中,具体可以自己修改&设置(比如说,对于充能操作,其奖励应该是在充满能量之后会设置为0,也就是说应该只有当前没有充满的时候,才会有相应的奖励(?
2. 下面何去何从?
开始的时候,学长就给出了如下的指导: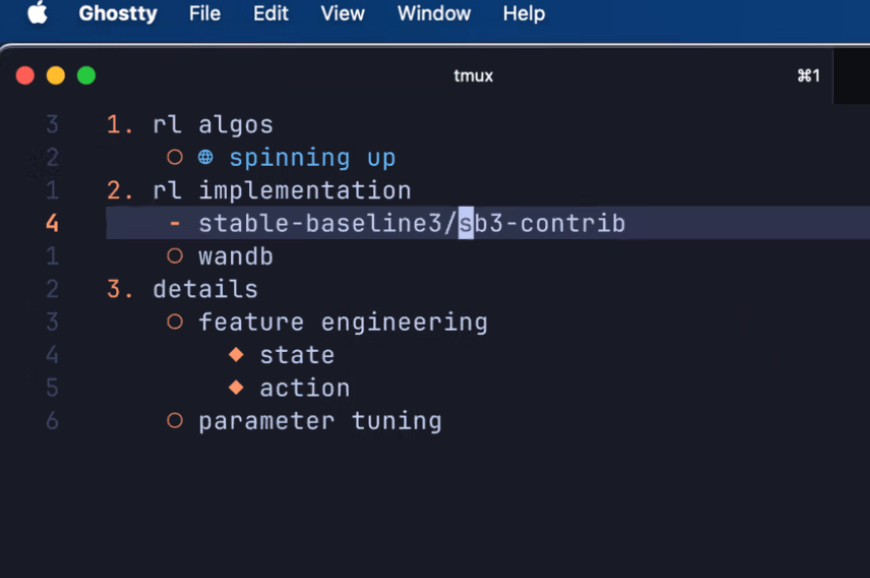 以这个为基础,我觉得目前面临的主要是以下三个挑战: 1. 卡牌问题和普通的RL问题很大的区别便是非马尔可夫性,也就是说,卡牌不同于我训练legged robot等等,没走一步都与之前的行为无关,而我的agent在玩卡牌的时候你先前步骤的决策和行为会影响后面的状态(和行为)(比如说,一个最简单的例子,我当前回合充了一个能量,接下来是否可以attack就取决于我之前的某个状态下的充能行为) 因此,对于这个“非马尔可夫性”,我是直接忽略这个问题,还是采取一定的方法解决它? 2. feature engineering 目前大量利用高维度向量和onr-hot编码表示的状态和动作或许太过于离散,(这样的坏处是什么?)如何优化现有的动作与状态表示? 并且,现有的代码open-ptcg框架是否可以丝滑应用于RL,eg,自动识别每个回合的结束? 3. parameter tuning:现有的(masked)PPO算法是否解决这个问题最合适?并且,采用的各个参数是否合适?
以这个为基础,我觉得目前面临的主要是以下三个挑战: 1. 卡牌问题和普通的RL问题很大的区别便是非马尔可夫性,也就是说,卡牌不同于我训练legged robot等等,没走一步都与之前的行为无关,而我的agent在玩卡牌的时候你先前步骤的决策和行为会影响后面的状态(和行为)(比如说,一个最简单的例子,我当前回合充了一个能量,接下来是否可以attack就取决于我之前的某个状态下的充能行为) 因此,对于这个“非马尔可夫性”,我是直接忽略这个问题,还是采取一定的方法解决它? 2. feature engineering 目前大量利用高维度向量和onr-hot编码表示的状态和动作或许太过于离散,(这样的坏处是什么?)如何优化现有的动作与状态表示? 并且,现有的代码open-ptcg框架是否可以丝滑应用于RL,eg,自动识别每个回合的结束? 3. parameter tuning:现有的(masked)PPO算法是否解决这个问题最合适?并且,采用的各个参数是否合适?
2.1 非马尔可夫性?
先读几篇可能有用的论文: 1.