读论文: LSTM: A Search Space Odyssey
LSTM: A Search Space Odyssey
这是一篇关于LSTM的论文;Odyssey,引申意自《奥德赛》(吗?),意为“艰难的跋涉,漫长的旅程”
(0)abstract
Learn some English 1. state-of-the-art: 目前最好的,最先进的
inception: 开端,创始
utility: 帮助,实用性
variants: 变体,变种
从摘要中总结看出,所谓的LSTM(长短期记忆)是一种RNN结构的变体,主要解决了RNN中常出现的梯度爆炸的问题;这篇文章主要使用了随机搜索方法探索了最优的超参数设置,发现了现有的LSTM变体中,没有模型可以很显著提升当前的标准LSTM架构。
(1)Introduction
Learn some English 1. hurdle: 障碍,困难
plague: 困扰,折磨(做v.时的意思)
acoustic: 声学的
incorporate: 集成,包含
其实主要内容于摘要很接近,稍微详细解释了一点 ## (1.5) 最基本的LSTM结构 在阅读下一个部分之前,首先来看一下LSTM模型的最基本的结构: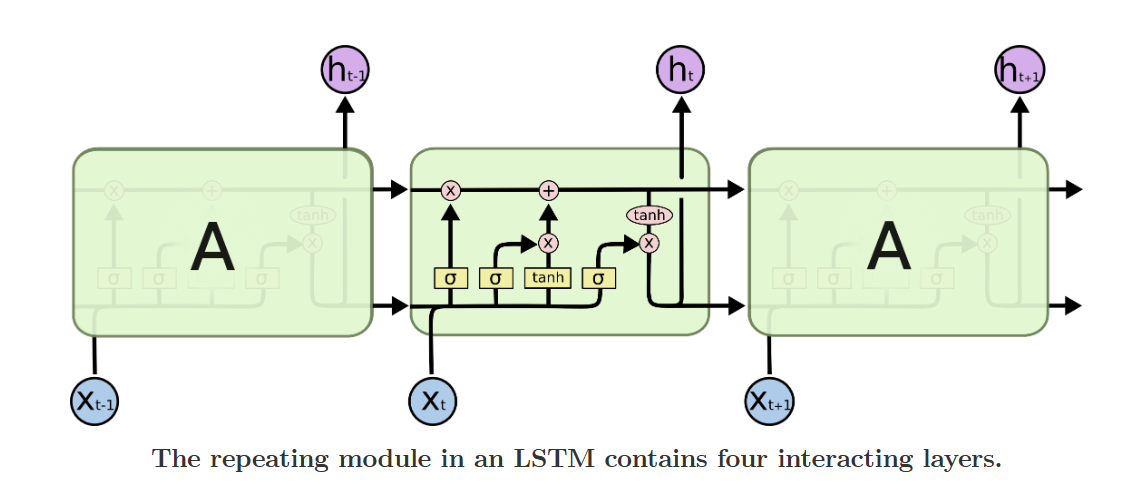 也就是说,与普通的RNN相比,其内部连接的结构会复杂得多。具体来说,分为以下几块详细进行讲解:
也就是说,与普通的RNN相比,其内部连接的结构会复杂得多。具体来说,分为以下几块详细进行讲解: 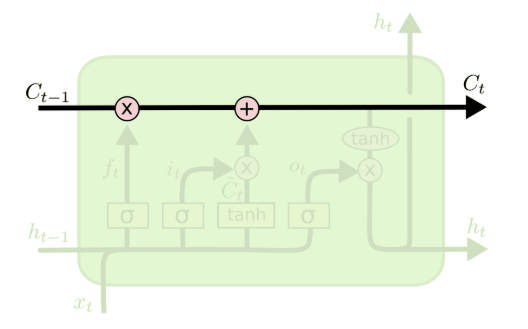 (0)LSTM的核心部分,比传统的RNN多的一个核心的地方就是引入了一个类似于“日记本”的结构Cell State,这个部分贯穿整个网络始终,并且只与网络作简单的线性交互。可以这么理解:RNN只能有短期的“记忆”,但是引入的这个“日记本”却能让我本来“健忘”的神经网络可以有一个长期的参照。 对于这个结构的修改,通过gate来进行,就是图上红色的圈圈部分。对于输入的内容,通过门和激活函数来控制Cell state中内容的变化。
(0)LSTM的核心部分,比传统的RNN多的一个核心的地方就是引入了一个类似于“日记本”的结构Cell State,这个部分贯穿整个网络始终,并且只与网络作简单的线性交互。可以这么理解:RNN只能有短期的“记忆”,但是引入的这个“日记本”却能让我本来“健忘”的神经网络可以有一个长期的参照。 对于这个结构的修改,通过gate来进行,就是图上红色的圈圈部分。对于输入的内容,通过门和激活函数来控制Cell state中内容的变化。 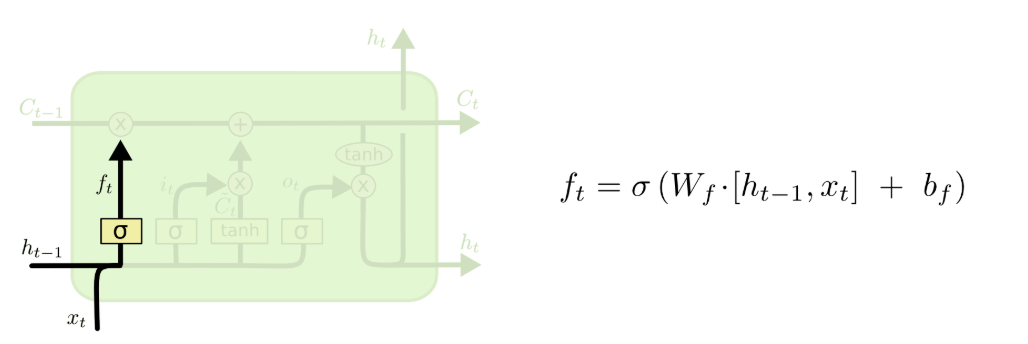 (1)LSTM的第一个部分被称为所谓的forget gate(忘记门) ,用于决定什么样的信息我们需要保留/删除:其接收前一个时间的输出ht − 1和当前时间的输入xt作为输入,并且使用sigmoid作为激活函数,输出一个0~1之间的值。 具体的计算来看,通过一个矩阵Wf和向量bf,将ht − 1和xt连接之后的结果通过计算之后得到一个向量ft,这个部分的意思就是,通过当前时间的输入和上一个时刻的内容,来决定之前我的“日记”中哪些内容是需要被删除的。
(1)LSTM的第一个部分被称为所谓的forget gate(忘记门) ,用于决定什么样的信息我们需要保留/删除:其接收前一个时间的输出ht − 1和当前时间的输入xt作为输入,并且使用sigmoid作为激活函数,输出一个0~1之间的值。 具体的计算来看,通过一个矩阵Wf和向量bf,将ht − 1和xt连接之后的结果通过计算之后得到一个向量ft,这个部分的意思就是,通过当前时间的输入和上一个时刻的内容,来决定之前我的“日记”中哪些内容是需要被删除的。 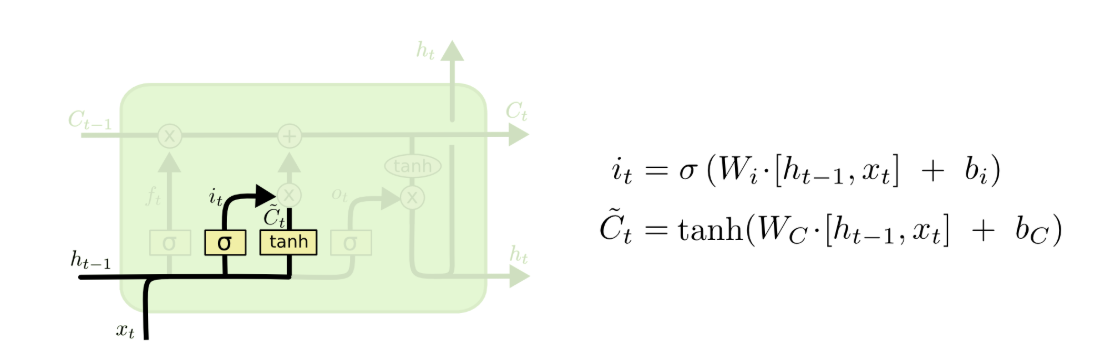 (2)有了前面的forget,下面一个就是storage gate(输入门) 了。如图所示,对于ht − 1和xt,通过sigmoid函数以及tanh函数进行计算之后,来决定哪些有用的内容是需要被我添加到“日记”中。
(2)有了前面的forget,下面一个就是storage gate(输入门) 了。如图所示,对于ht − 1和xt,通过sigmoid函数以及tanh函数进行计算之后,来决定哪些有用的内容是需要被我添加到“日记”中。
为了更方便理解,以使用LSTM理解文本为例,在我们的网络中有两种不同的向量: 1. 单词编码得到的向量,这是实现人为定义好的(比如说,使用word2vec等等技术),输入向量是人为确定的嵌入内容 2. 文本向量,也就是Ct,这个向量的维度是设定的超参数(通常与之前的维度相同,或者是512?)各个维度代表的意义是在模型训练中自己学习得到的 在LSTM计算的过程中,会输入嵌入过的词向量,然后根据计算的方法来决定在我的cell中有原有的向量各个维度需要被增加或者删除多少,在后续的步骤中进行加权计算后更新。
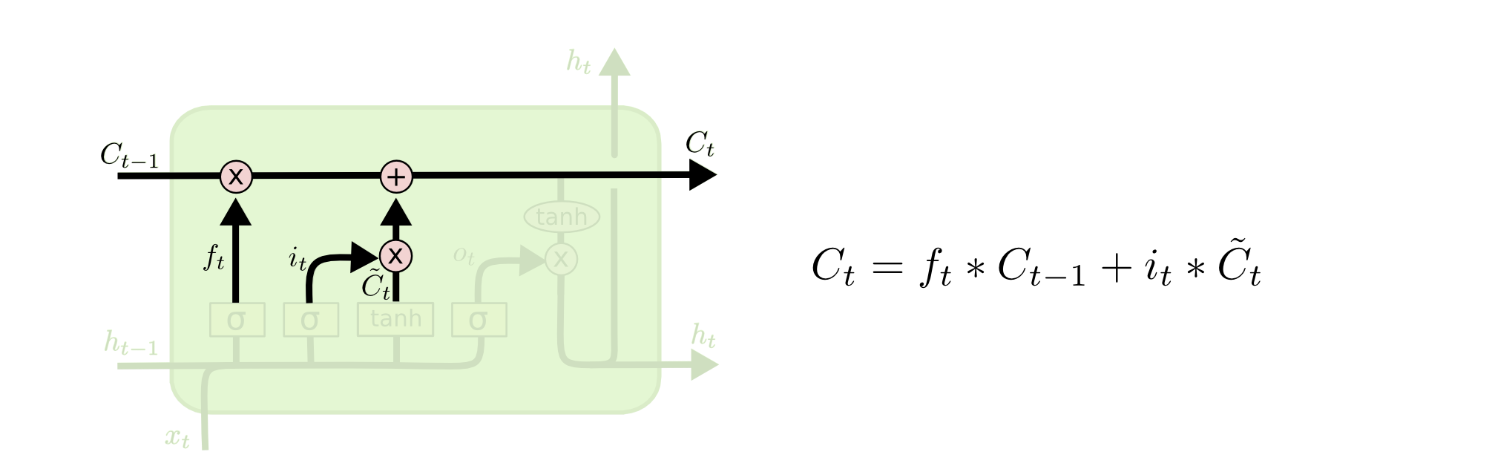 (3)第三个步骤就是根据上面计算的内容,相应更新Ct − 1到下一个stateCt了。如图所示的计算,前面计算的向量ft就是上一个状态遗忘之后的权重,因此乘以Ct − 1,代表前一个状态被保留下来的部分;storage gate中计算的input值it与Candidate value$\tilde{C_t}$相乘,作为当前时刻新增的输入值增加到日志中。(本质上看,相应更新的内容都是维度的权重)
(3)第三个步骤就是根据上面计算的内容,相应更新Ct − 1到下一个stateCt了。如图所示的计算,前面计算的向量ft就是上一个状态遗忘之后的权重,因此乘以Ct − 1,代表前一个状态被保留下来的部分;storage gate中计算的input值it与Candidate value$\tilde{C_t}$相乘,作为当前时刻新增的输入值增加到日志中。(本质上看,相应更新的内容都是维度的权重) 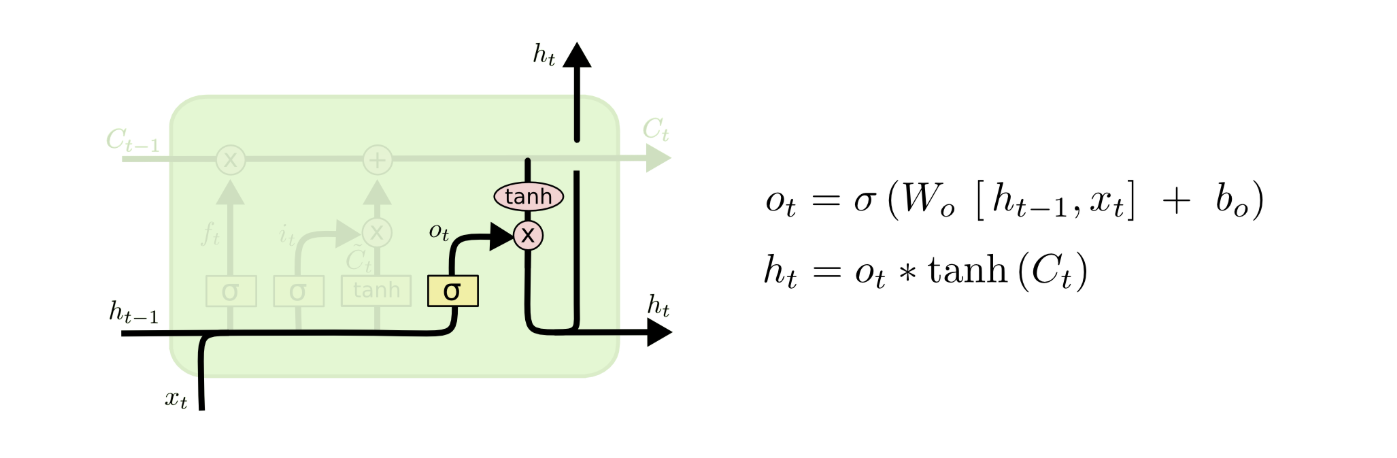 (4)最后一个部分就是所谓的output gate(输出门) 了,这个部分输出当前对应的神经网路输出的ht;首先使用sigmoid进行和上面类似的矩阵类型的计算,然后乘以tanh函数(把这个值调整到[ − 1, 1]区间之间),之后输出得到下一个状态的h值。 到这里为止,一个基本形态的LSTM网络就完成了。
(4)最后一个部分就是所谓的output gate(输出门) 了,这个部分输出当前对应的神经网路输出的ht;首先使用sigmoid进行和上面类似的矩阵类型的计算,然后乘以tanh函数(把这个值调整到[ − 1, 1]区间之间),之后输出得到下一个状态的h值。 到这里为止,一个基本形态的LSTM网络就完成了。 在先前的LSTM模型中,主要使用到的激活函数均为sigmoid与tanh,这是根据他们不同的特性决定的:sigmoid输出值为0~1之间,这样方便表示保留的权重信息(也就是说,百分之多少被保留,etc.);而tanh具有在对称区间输出的特点,因此,再比如说candidate value的地方使用tanh进行激活,可以相应地记录保留的什么值是“正向”或是“负向”的。
(2)VANILLA LSTM
vanilla不仅仅是熟悉的“香草”意思,作形容词的时候还有“普通的,平淡无奇”之意!  从这篇文章中对于vanilla LSTM的定义可以看出,这些权重矩阵
从这篇文章中对于vanilla LSTM的定义可以看出,这些权重矩阵